






Turning Sensitive Documents into Safe, Shareable Assets
Client background
Our client is a global software provider handling large volumes of customer documents across industries. These files often contained personally identifiable information (PII) such as names, IDs, financial details, and images with sensitive content.
To comply with privacy regulations and reduce business risk, the client needed a reliable way to detect, preview, and anonymize this data - without breaking document integrity or slowing workflows.
Business challenge
Existing redaction tools were either inaccurate, slow, or disruptive to formatting. The client asked us to build an anonymization system that could:
- Detect sensitive information in both text and embedded images.
- Allow users to review and select what should be masked.
- Preserve original formatting, layout, and styles.
- Operate at scale across different document types (PDF, DOCX, RTF, images).
- Integrate seamlessly into their existing software suite.
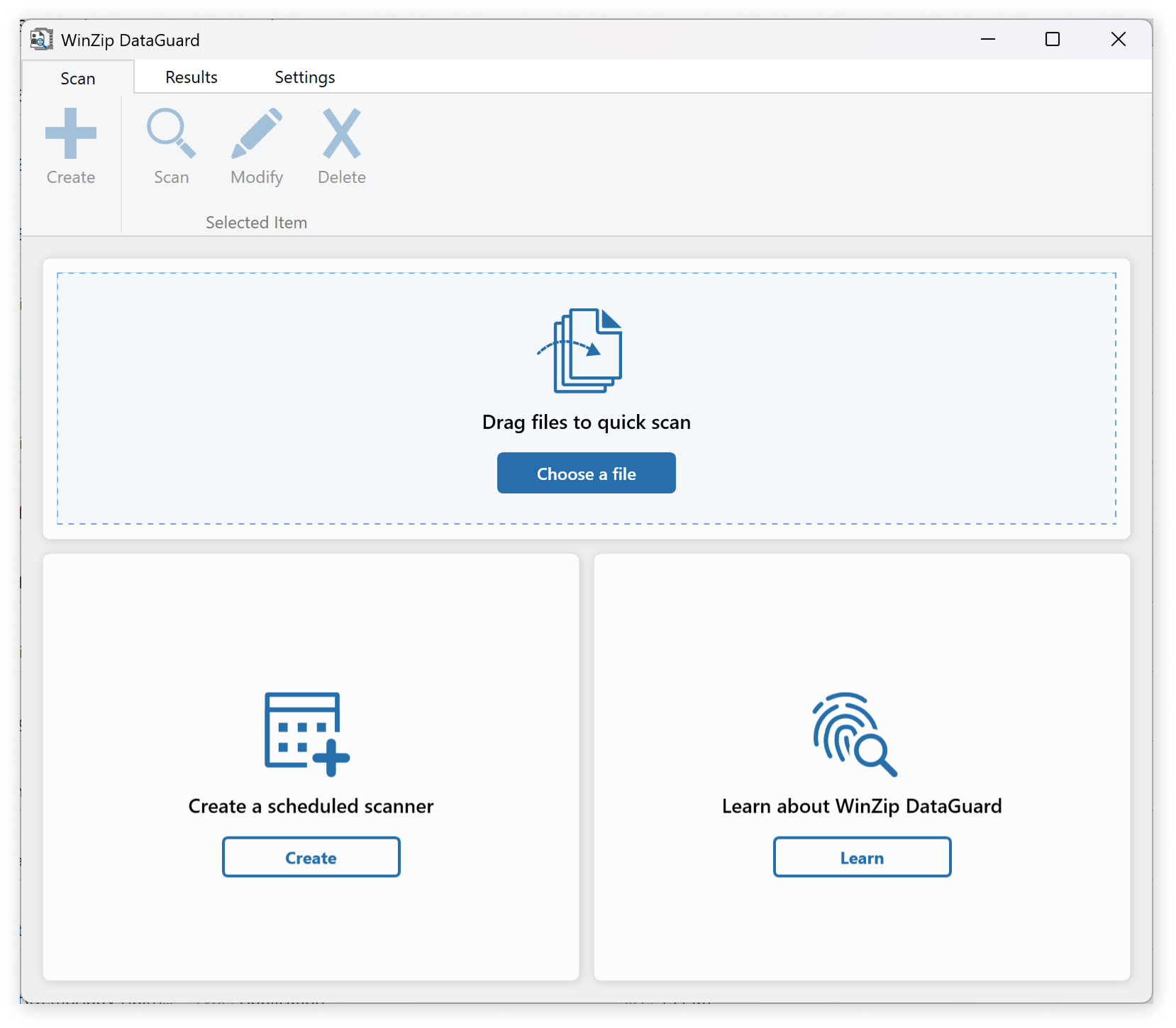
How did we make it work?
We designed a modular pipeline using Docker containers, each responsible for a single stage of the anonymization process.
- Data ingestion: Files uploaded and queued via RabbitMQ.
- Extraction: Containers pulled text and images using Aspose and OCR libraries.
- Detection: Microsoft Presidio analyzed extracted content to identify PII elements.
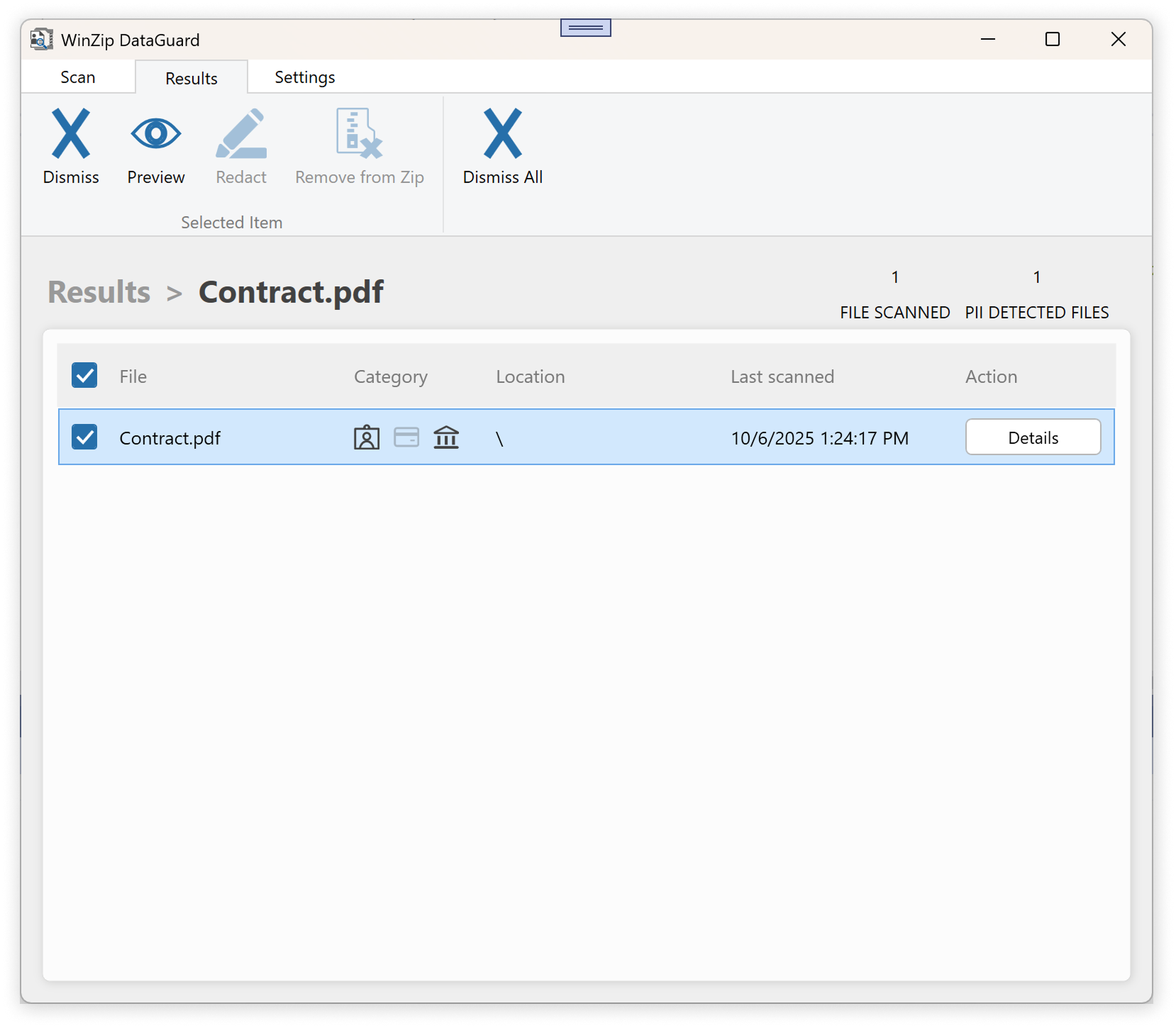
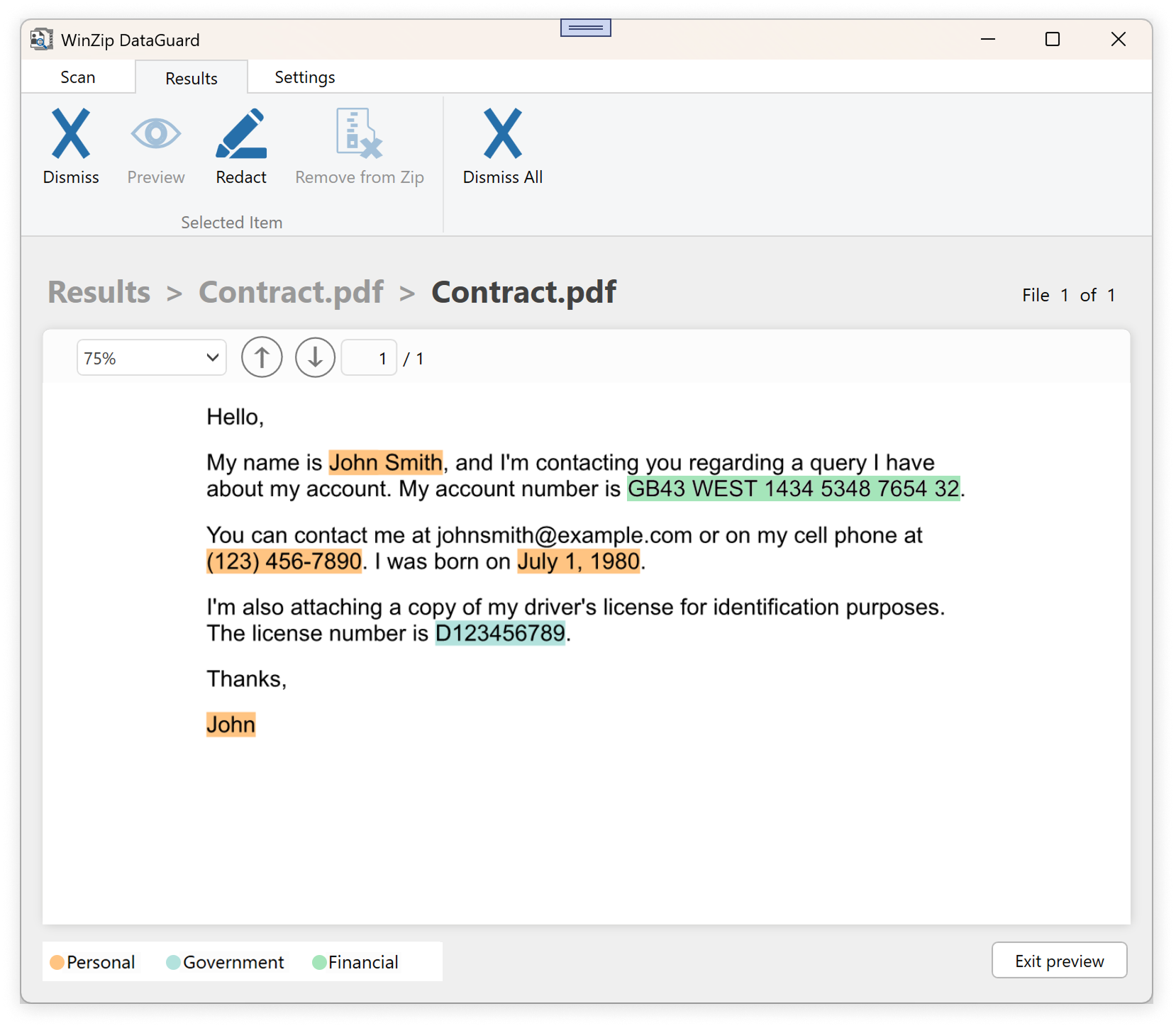
- Preview UX: The original file was reconstructed with sensitive fields highlighted for user review.
- Redaction: Based on user selection, text and images were masked with placeholders while preserving layout.
- Delivery: The anonymized file was exported back in its original format, ready for secure use.
Main technical challenges
01 Hybrid Windows/Linux containers

We designed a modular pipeline using Docker containers, each responsible for a single stage of the anonymization process.
02 Document layout preservation
Redaction often breaks structure. We developed rendering logic that maintained spacing, styles, and formatting so that the final file looked identical to the original.
03 Responsive preview at scale
Processing large, complex documents needed speed. We optimized orchestration and caching to deliver near real-time previews.
04 Cross-format support
Handling multiple formats (PDF, DOCX, RTF, images) required format-aware parsing and transformation while keeping consistency across outputs.
05 High-volume performance
Client documents often carried hundreds of pages, embedded images, and layered formatting.
Without optimization, anonymization would stall or corrupt layouts. We engineered the pipeline to process large, complex files smoothly, so users could keep working without delays and companies could trust the results for compliance and client-facing use.
Value delivered by devPulse
- Privacy compliance
enabled GDPR/HIPAA-ready workflows with accurate PII detection.
- Future-proof modularity
microservices allowed independent upgrades without downtime.
- Seamless integration
easily embedded into the client’s existing software products.
- User-controlled anonymization
preview interface gave flexibility and transparency.
- Faster data handling
high throughput made anonymization practical at enterprise scale.
Development Timeline
4 months
Team Composition
- 2 Full-stack Developers
- 1 QA Engineer
- 1 Product Manager
- 1 Designer
- 1 DevOps
Technology
- C/C++
- Presidio
- C#
- Aspose
- Python
- RabbitMQ
- WPF
- MinIO
- Docker (Windows + Linux)

