








Updated April, 2025
Global cloud spend will top $679 billion in 2024, Gartner projects, yet many enterprises still struggle to realise value. A cloud migration strategy aligns technical moves with business outcomes-speed-to-market, resilience, cost control-so you invest in advantage, not just infrastructure. In practice, that strategy must connect three threads: a frank audit of legacy workloads, a principled choice among the 7 Rs migration patterns, and an execution plan that bakes in security and FinOps from day one. This concise guide distils hard-won lessons from Capital One, Netflix, Coca-Cola Andina, HSBC, and Expedia so you can assess, plan, and iterate with confidence rather than hope.
Why a Strategy Beats Ad-Hoc Lift-and-Shift
Forrester found 73 % of enterprises that skipped a holistic plan had to roll critical workloads back on-prem within 24 months-an expensive U-turn that erodes executive faith in cloud. The pattern is predictable: teams re-host VMs, overlook hidden dependencies, and watch costs spiral when 24.7 instances meet cloud pricing. By contrast, firms that tie migration work to business KPIs-lower incident MTTR, faster product launches-report time-to-value twice as fast.
A disciplined strategy covers three lenses:
Business fit. Map each workload to revenue impact or regulatory risk; de-prioritise anything that doesn’t move the needle.
Technical feasibility. Classify apps against the upcoming 7 Rs (Rehost, Replatform, Refactor, etc.) to avoid reflex lift-and-shift.
Operating model. Define ownership for FinOps, security, and release engineering before the first byte moves.
Competitors that still treat migration as a pure infrastructure exercise rarely sustain savings; Akamai’s and BytePlus’s own reports show cost overruns of 20-35 % when governance lags deployment. Treat strategy as a living artefact -review quarterly alongside your wider digital transformation strategy -and lift-and-shift becomes a tool, not a trap.
Rapid Assessment Framework
A credible strategy starts with an evidence-based assessment-not a best-guess spreadsheet. Capital One’s migration team captured it bluntly: “Do the hard part first.” They front-loaded the discovery of messy, business-critical workloads rather than cherry-picking easy wins, cutting overall timeline slippage by 30 percent.
2.1 Three lenses for rapid discovery
| Lens | What you capture | Why it matters | Example tools |
| Business criticality | Revenue impact, compliance scope, user exposure | Prioritises work that moves a KPI, not vanity metrics | AWS Migration Evaluator, Azure Migrate Business Case |
| Technical complexity | Language, framework age, integration surface, test coverage | Flags refactor candidates early and avoids blind lift-and-shift | CAST Highlight, Google Cloud Application Discovery |
| Operational reality | True utilisation, burst patterns, incident history | Builds accurate cost and resilience models | CloudWatch, Datadog, Dynatrace |
Rapid tip: Automate wherever possible. Capital One’s in-house crawler mapped 4,000 servers in 48 hours-manual interviews would have taken months.
2.2 Interdependencies checklist
Use this quick scan before classifying any workload:
- Inbound APIs: Which services or partners call this app in production?
- Outbound data flows: Does it push to message queues, FTP drops, or BI stacks?
- Shared databases: Are multiple apps writing to the same schema or replica set?
- License ties: Does the software license limit where the workload can run?
- Latency sensitivity: What happens if round-trip time jumps from 2 ms to 20 ms?
- Security zones: Is the app subject to PCI, HIPAA, or regional data-sovereignty rules?
- Batch windows: Do nightly jobs collide with planned cut-over slots?
- Hidden crons & daemons: Any scripts on legacy boxes nobody has touched in years?
- Hard-coded IPs & paths: Will DNS or path rewrites break runtime calls?
- Ops muscle memory: Which break-glass runbooks assume on-prem tooling?
2.3 Rationalise – then score
Feed the checklist insights into a weighted matrix: business value (40 %), complexity (30 %), risk (20 %), migration cost (10 %). Scores reveal which apps you should retain, retire, rehost, or refactor-the gateway to the upcoming 7 Rs section.
When legacy code demands deeper re-engineering, see our guide on modernizing legacy systems for a pragmatic playbook.
With this framework in place, you move from opinion to data-backed sequencing-clearing the runway for the 7 Rs migration patterns we’ll tackle next.
Cloud Migration Strategies – The 7 Rs
Choosing the right migration pattern for each workload prevents budget blow-outs and post-cut-over fire-drills. AWS popularised the 7 Rs framework – now industry standard – for mapping applications to the most pragmatic path AWS’s 7 Rs of cloud migration. Below is a brief, decision-ready guide for enterprise teams.
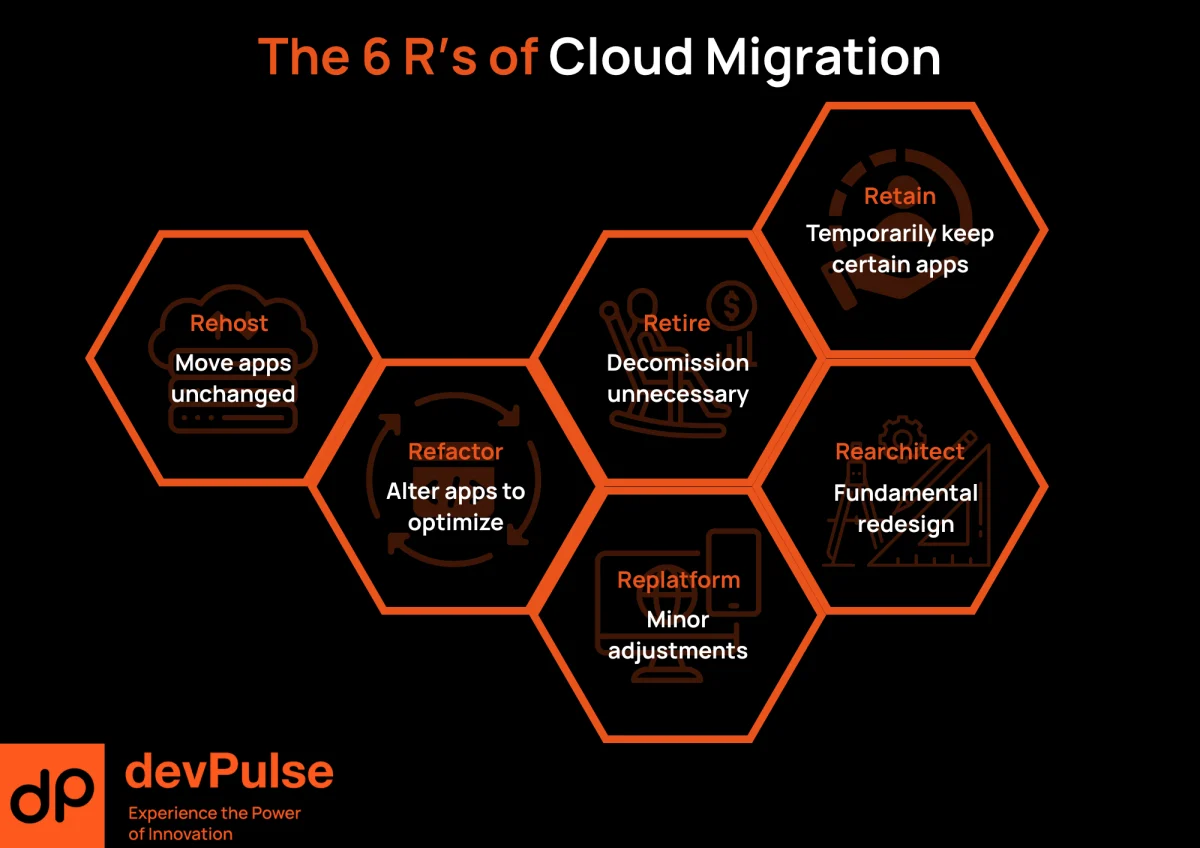
Rehost (Lift-and-Shift)
Move virtual machines as-is to IaaS.
When it fits: tight data-centre exit deadlines, dev/test environments, apps slated for decommission within 18 months.
Watch-out: 20- 30 % cost creep if you forget to right-size instances and schedule non-production shut-downs.
Replatform (Lift-tinker-and-Shift)
Keep the core code but swap underlying components – e.g., migrate from self-managed SQL to RDS or from WebLogic to Tomcat.
When it fits: the app needs quick wins (managed services, autoscaling) without a full rewrite.
Benefit: cuts ops toil fast and typically trims cloud spend 10-20 % versus pure rehost.
Repurchase (Move to SaaS)
Replace the application entirely with a SaaS product (e.g., on – prem CRM → Salesforce).
When it fits: commodity capabilities that no longer differentiate the business.
Key metric: total cost of ownership parity within three years, including licence and change-management expense.
Refactor / Rearchitect
Rewrite significant portions – or the whole stack – to exploit cloud-native patterns (microservices, event-driven, serverless).
When it fits: scaling barriers, frequent releases, or critical feature velocity.
Payoff: >50 % reduction in incident MTTR and faster innovation cadence (Netflix’s experience).
Risk: longer lead time; ring-fence budget and stage releases behind feature flags.
Relocate
Shift entire VMware estates to VMware-on-Cloud without converting VMs first.
When it fits: large VM farms that need rapid evacuation from data centres and where refactoring is cost-prohibitive.
Trade-off: operational familiarity at the expense of missing cloud-native savings until later optimisation.
Retain
Keep the workload on-prem-at least for now.
When it fits: ultra-low-latency systems sitting next to plant equipment, or heavily customised ERP with upcoming vendor upgrade.
Next step: schedule a re-evaluation checkpoint; retaining is a decision, not neglect.
Retire
Decommission redundant apps, scripts, or servers outright.
When it fits: duplicated functionality, obsolete reporting, or shadow IT discovered during assessment.
Quick win: immediate licence and hardware savings fund more complex migrations.
Decision shortcut: Score each workload on business value, technical debt, and risk appetite. If the totals cluster around 70 % or more on value and risk tolerance, invest in Refactor; if they under-index on strategic value, gravitate to Retire or Retain. For mixed portfolios, blend strategies-Capital One ran lift-and-shift for dev/test while refactoring customer-facing systems, accelerating time-to-cloud without derailing critical revenue streams.
Five-Step Migration Process
A clear, gated roadmap keeps risk low and stakeholders aligned. Use the sequence below as a cookbook-you don’t leave one step until the exit criteria are met.
- Assessment → evidence
- Automate discovery (AWS Migration Hub, Azure Migrate) to capture utilisation, dependencies, licence limits, and business impact.
- Outcome: a prioritised backlog and first-pass cost model that map each workload to one of the 7 Rs.
- Planning → commitments
- Turn backlog items into epics with owners, budgets, and “definition-of-done” KPIs (latency, rollback, cost guardrails).
- Draft identity, tagging, and FinOps policies now-retro-fitting is expensive.
- Sync each epic with an agile transformation cadence so two-week increments expose drift early.
- Pilot → proof
- Pick a dependency-rich but non-critical app as a pilot.
- Validate cut-over mechanics, monitoring coverage, and incident runbooks.
- Success metric: zero unplanned downtime and cost variance < 10 % versus forecast. Capture lessons; fold them back into code and playbooks.
- Migration → scale
- Roll out in waves-by business unit, domain, or risk profile.
- Use blue-green or canary releases to shift traffic gradually.
- Enforce infrastructure-as-code so every stack is reproducible; let drift detection trigger pipelines, not pager duty.
- Optimisation → compounding value
- Rightsize instances, tier storage, and enforce auto-scaling. Expedia cut cloud spend 45 % within nine months through continuous rightsizing.
- Bake FinOps reviews into sprint retrospectives, then modernise runtimes-containers, service mesh, event frameworks-to close the gap with a modern tech stack.
- Feed performance data back into your backlog; the loop turns migration from a one-off project into a strategic capability.
By forcing each gate to prove value-evidence → commitments → proof → scale → optimisation-you avoid the “migrate → regret” pattern and build repeatable muscle for the years of cloud evolution still ahead.
Common Challenges & Practical Mitigations
| Challenge | Why it blindsides teams | One-sentence fix |
| Cost overruns – 82 % of enterprises blow past their first-year cloud budget, Flexera’s 2025 State of the Cloud Report notes. | Lift-and-shift VM sizes rarely match real usage; reserved capacity and spot pricing are afterthoughts. | Embed a FinOps review in every sprint and right-size/turn off idle resources after 30 days of telemetry. |
| Unplanned downtime during cut-over | Hidden dependencies or DNS TTLs stall traffic; rollback paths are untested. | Run a blue-green or canary pilot and include failure drills before the public switchover. |
| Identity fragmentation across hybrid estates | Separate on-prem AD, cloud IAM, and SaaS roles create “ghost” accounts attackers exploit. | Bridge directories early, enforce SSO, and monitor for orphaned credentials in both realms. |
| Configuration drift post-migration | Manual tweaks patch urgent issues but leave Terraform out of sync; security baselines erode. | Treat IaC as the single-source-of-truth; drift detection pipelines must auto-create PRs or block deploys until reconciled. |
| Vendor lock-in fear stalls executive sign-off | CFOs worry exit costs will negate projected savings. The New Stack Cloud Adoption Survey 2024 shows 43 % cite lock-in as their top concern. | Design portable layers-Kubernetes, open-source build pipelines, abstraction of data stores-so workloads can redeploy across clouds if economics shift. |
Related resource: If technical debt makes drift and downtime more likely, see our playbook on modernizing legacy systems for phased refactoring tactics.
Addressing these five pitfalls upfront prevents the post-migration fire-drills that erode stakeholder confidence-and keeps your roadmap focused on business value instead of rework.
Cost & ROI Engineering
Cloud economics reward precision, not hope. Flexera’s 2025 State of the Cloud Report shows 61 % of enterprises now run dedicated FinOps teams to rein in wasted spend – and those teams claw back a median 20 % of annual cloud costs (2025 State of the Cloud Report). Expedia proves the upside: after shifting to AWS they cut compute spend 45 % while handling a 10x traffic surge, thanks to aggressive rightsizing, spot-instance pools, and Graviton migrations.
Quick storage economics check
| Tier scenario | GB/month rate | 1 TB monthly cost | Annual cost | Savings vs. baseline |
| S3 Standard (baseline) | $0.023 | $23.00 | $276.00 | – |
| S3 Infrequent Access | $0.0125 | $12.50 | $150.00 | 46 % |
| Glacier Instant Retrieval | $0.004 | $4.00 | $48.00 | 83 % |
Action: run a 30-day utilisation scan, then auto-tier anything older than 30 days to Glacier Instant Retrieval. The move takes one line in your lifecycle policy and pays for itself in a single billing cycle.
Four levers every FinOps review should pull
- Rightsize + de-schedule Kill zombie instances; downshift over-provisioned ones.
- Commit where predictable Reserved or Savings Plans for steady loads; keep bursty work on demand.
- Exploit spot markets Non-prod and batch jobs can ride 70 % discounts with minimal interruption risk.
- Shift to efficient silicon Expedia’s switch to AWS Graviton saved $66,000 per 100 instances per year without code rewrites.
Pro tip: Surface these metrics in your sprint retrospectives. A two-minute FinOps check saves more budget than a week-long optimisation project caught too late.
With cost visibility engineered into every backlog item, migration budgets stop being a gamble and start compounding-fuel you can redirect into larger-horizon initiatives like AI-driven optimisation or edge deployments.
2025 Trends to Watch
| Trend | Why it matters in 2025 | Signal to track |
| AI-driven migration tooling | Cloud vendors now bundle schema conversion, test-case generation, even IAM hardening into GenAI copilots, shrinking discovery and refactor sprints from weeks to hours. | Forrester forecasts a 40 % jump in adoption of AI-powered cloud services by year-end 2025. Wipro IT Solutions |
| Kubernetes as the new default runtime | IDC notes explosive growth in container estates as orgs shift data-heavy AI/ML workloads onto managed K8s, forcing Ops to master cost and observability at pod level. | IBM/IDC analysis highlights that K8s “ubiquity will continue to grow exponentially” through 2025. IBM – United States |
| FinOps goes mainstream | When every sprint shows a dollar figure, engineers optimise early; 59 % of enterprises now have a formal FinOps team, up from 51 % last year. | Flexera State of the Cloud 2025. info.flexera.com |
| Edge adoption accelerates | Low-latency AI inference and local data compliance push workloads closer to users; analysts expect 40 % of large enterprises to embed edge computing into their core architecture in 2025. | Forbes Tech Council edge-computing forecast. Forbes |
Take-away: these trends compress migration timelines but raise governance stakes. Bake AI tooling reviews, K8s cost controls, FinOps cadences, and edge-friendly architectures into your roadmap now-so 2025’s wave of innovation grows value instead of complexity.
Mini Case Study – Coca-Cola Andina
Context. Latin-American bottler Coca-Cola Andina ran siloed SAP, CSV, and legacy DB workloads across four countries, slowing analytics and stock-level decisions.
Strategy.
- Assessment. Automated discovery mapped data flows from 10 plants and ~100 distribution centres.
- “7 Rs” mix. 70 % of systems Replatformed onto managed Amazon S3 + Redshift; 20 % Refactored for serverless analytics; 10 % legacy reports Retired.
- Phased roadmap. Built a central data lake first, then layered Amazon QuickSight dashboards and ML personalisation (Amazon SageMaker).
- FinOps guardrails. Tiered cold data to Glacier Instant Retrieval; weekly rightsizing reviews kept spend < forecast.
Outcomes.
- 80 % jump in analytics-team productivity – insights delivered in minutes, not hours.
- 95 % of enterprise data unified in the lake, enabling cross-market promotions.
- Revenue uplift from smarter discount targeting and 0.2 % drop in out-of-stock events. (Amazon Web Services)
Coca-Cola Andina’s phased approach mirrors this guide: assess first, pick the right “R” per workload, and bake FinOps into every sprint.
Post-Migration Optimisation Spiral
Cloud migration isn’t a finish line; it’s the on-ramp to a multi-year optimisation loop that compounds value each quarter. Netflix’s seven-year AWS journey shows how continuous improvement, not “big-bang” cut-over, delivers transformative ROI.
| Phase | Focus | Netflix proof-point | What to copy |
| 1 x Stabilise | |||
| (0-6 months) | Baseline performance, expand monitoring, script automated recovery | Chaos Monkey suite slashed streaming outages 70 % in the first six months after migration | Establish SLOs, automate rollbacks, enforce observability before scaling |
| 2 x Optimise | |||
| (3-12 months) | Rightsize, reserve capacity, refactor hot paths | Rightsizing + reserved instances cut compute cost ~45 % while traffic kept rising | Run monthly FinOps reviews; treat every sprint retro as a cost-saving hunt |
| 3 x Accelerate | |||
| (6-24 months) | Self-service infra, predictive autoscale, CI/CD velocity | Internal platform “Spinnaker” pushed deployment frequency from weekly to thousands per day | Bake golden-path pipelines; let teams spin environments without Ops tickets |
| 4 x Transform | |||
| (18 + months) | New business models, global reach, data-driven products | From 2007-2015 Netflix streamed 1 000x more hours and grew subscribers 8x, all on AWS increment.com | Free capacity for innovation: launch net-new AI, edge, or data-mesh services |
Key metric shift: after Phase 1 the north-star changes from uptime to change-rate-how safely and cheaply you can iterate code, architecture, and cost levers.
Building your own spiral
- Instrument everything. If a metric isn’t captured in Phase 1, you can’t optimise it in Phase 2.
- Automate waste-killing. Idle-resource policies and drift detectors pay for themselves faster than any manual review.
- Promote platform thinking. Self-service pipelines let product teams innovate without waiting on central Ops.
- Reinvest the delta. Savings from rightsizing fund container-mesh pilots and modern tech-stack upgrades.
Netflix ended its migration with over 100 million members streaming 125 million hours daily (Amazon Web Services, Inc.)-not by “moving to cloud” once, but by climbing this spiral quarter after quarter. Adopt the same mindset and your migration becomes a runway, not a one-off project.
Alternative Futures – Multi-Horizon Modernisation
Migration yields its biggest returns when the roadmap anticipates more than one technological future. Map your investments across four overlapping horizons, each unlocking a distinct set of capabilities and risks.
| Horizon | Time frame | Primary benefit | First practical step |
| Container-centric | 6-18 months | Consistent runtimes, faster deploys, higher density | Standardise builds on Docker, run a managed Kubernetes pilot. |
| Event-driven / Serverless | 18-36 months | Eliminates idle capacity for spiky workloads; reduces ops toil | Identify functions with burst traffic (e.g., image resizing) and move to FaaS on a limited scale. |
| AI-augmented Ops | 3-5 years | Predictive scaling, anomaly detection, self-healing pipelines | Stream full telemetry-logs, traces, cost-to a central data lake; train simple drift-detection models first. |
| Quantum-assisted workloads | 5-10 years | New classes of optimisation and simulation once infeasible on classical hardware | Partner with cloud-provider sandbox programmes; test hybrid quantum algorithms on R&D datasets. |
How to allocate effort
- 70 % to incremental container and serverless rollout-today’s cost and velocity levers.
- 20 % to AIOps pilots-focus on one high-noise service and measure false-positive reduction.
- 10 % to long-range experiments-quantum, photonics, or edge ASICs as budgets allow.
Link the journey: each horizon builds on the previous one’s automation foundations. Our modern tech stack guide details reference architectures that keep layers swap-friendly, so today’s container investment doesn’t block tomorrow’s AI scheduler.
Decision checkpoint
Review the portfolio every quarter:
- Business fit – does a new horizon solve an urgent customer or efficiency problem?
- Talent readiness – do teams have the skills or partners lined up?
- Economic trigger – have costs, licensing, or market forces tipped the value equation?
Planning across horizons turns “future proofing” from a slogan into a measurable backlog item-ensuring your cloud foundation keeps pace with the next decade of platform shifts.
Quick Cloud Migration Checklist
- Secure an executive sponsor and write down the business KPIs the move must hit.
- Inventory every workload, dependency, and licence; score each with the 7 Rs matrix.
- Build an initial cost model and set FinOps alerts for ±10 % budget drift.
- Define a single sign-on plan and least-privilege IAM baseline before any data leaves the building.
- Automate the landing zone: network, tagging, logging, and encryption defaults.
- Pick one pilot app and script a blue-green cut-over with a tested rollback path.
- Stand up full observability-metrics, traces, logs-and verify alerts reach the right on-call engineer.
- Schedule a rightsizing review 30 days after cut-over to kill idle spend early.
- Update disaster-recovery runbooks and run a game-day to prove RPO/RTO targets.
- Capture lessons learned and feed them straight into the backlog for the next migration wave.
FAQs
A cloud migration strategy is a documented plan that maps each workload to its most suitable migration pattern (“7 Rs”), aligns the project with specific business KPIs, and sets guardrails for security, cost, and operations. It removes guess-work by turning high-level goals—faster releases, lower CapEx—into a sequenced backlog that engineering, finance, and risk teams can follow.
Rehost
Fast exit from a data centre without code changes.
Replatform
Swap underlying services (e.g., self-managed DB → managed DB) to cut ops toil.
Repurchase
Replace the app outright with SaaS.
Refactor / Rearchitect
Rewrite to exploit cloud-native patterns such as microservices or serverless.
Relocate
Move whole VM estates to VMware-on-cloud when refactor budget is tight.
Retain
Keep an app on-prem for now—usually due to latency or compliance constraints.
Retire
Decommission redundant or low-value workloads.
Time frames vary by portfolio size and complexity, but large organisations usually see:
Pilot phase: 3–6 months to validate tooling, cut-over, and rollback.
Bulk migration: 6–18 months, often delivered in three-to-six-week waves.
Optimisation loop: continuous; rightsizing and architecture upgrades start 30 days post cut-over and run for the life of the platform.
Projects finish closer to the shorter end of the range when they automate discovery, enforce infrastructure-as-code, and embed FinOps reviews from the first sprint.

