







Updated April, 2025
Implementing DevOps is often portrayed as a straightforward task: automate deployments, add a few tests, and success should follow. Yet, analysts estimate that up to 75% of DevOps transformations do not achieve their intended results, often due to cultural and strategic gaps. This discrepancy arises when organizations focus on tooling hype instead of asking a fundamental question: How will each DevOps decision improve our software delivery?
Below, you’ll find a practical look at DevOps implementation strategies that address real production challenges. Along the way, we’ll explore automation, observability, security, platform engineering, and best practices for scaling. We’ll also reference our own experiences, industry research, and related resources-like our Agile Transformation Roadmap and digital transformation guide-to help you navigate the shift to modern delivery pipelines.
Why DevOps Fails-and How to Succeed
DevOps’ central promise is faster, more reliable software delivery. According to the latest DORA (DevOps Research and Assessment) data, elite-performing teams can deploy code nearly 1,000 times more frequently than low performers, with far faster incident recovery. However, simply choosing a CI/CD tool doesn’t make that happen.
Three common pitfalls stand in the way:
- Treating DevOps as a Tools-Only Exercise: Many teams install a pipeline tool, write a few test scripts, and expect major gains. Tooling does matter, but results hinge on workflows, culture, and business alignment.
- Ignoring Organizational Resistance: Without buy-in from leadership and clear communication across teams, DevOps efforts stall. Teams must understand why they are changing processes.
- Failing to Integrate Security and Observability: DevOps is more than automating deployments. It includes continuous feedback and risk management at every stage.
Our recommendation is to anchor every DevOps initiative to a measurable goal-such as reducing cycle time or lowering the cost of a release. This ensures you’re not automating for automation’s sake but driving real business outcomes.
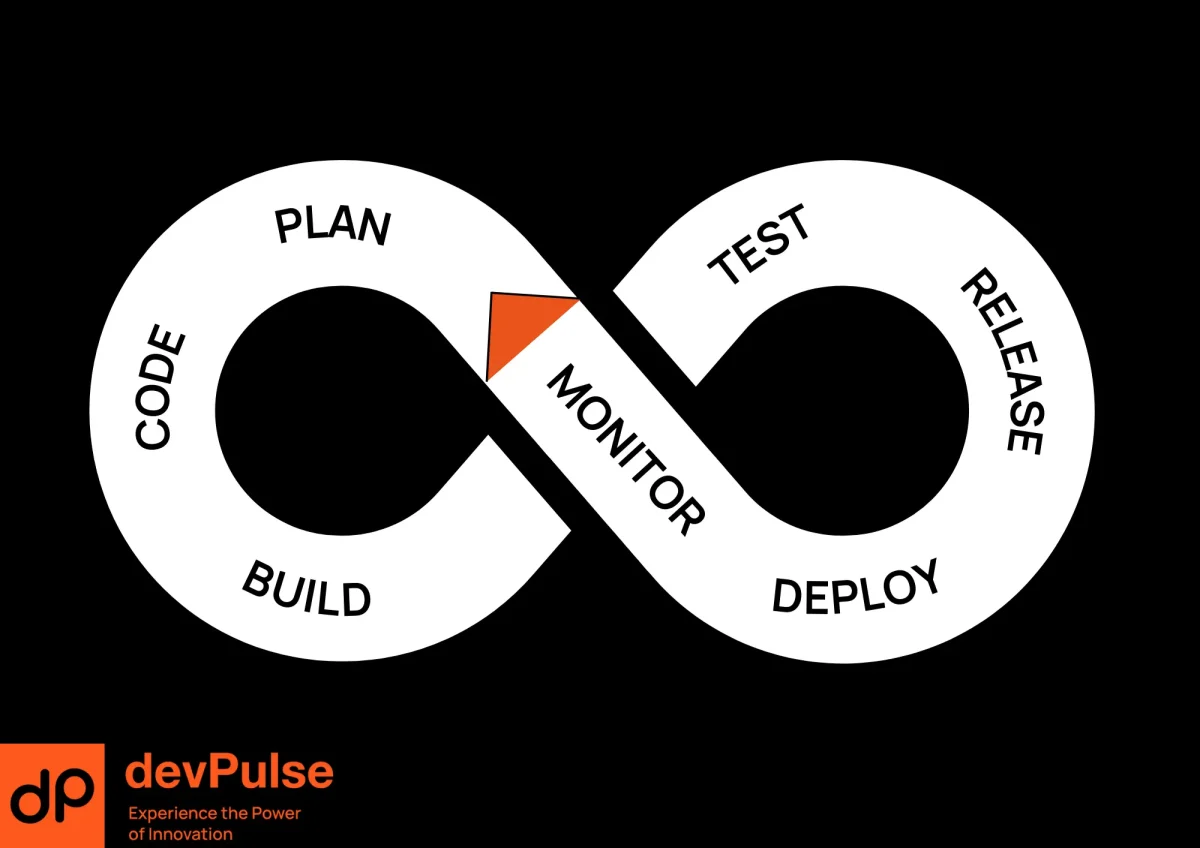
Four Pillars of Successful DevOps
1. Automated Pipelines With Real Business Impact
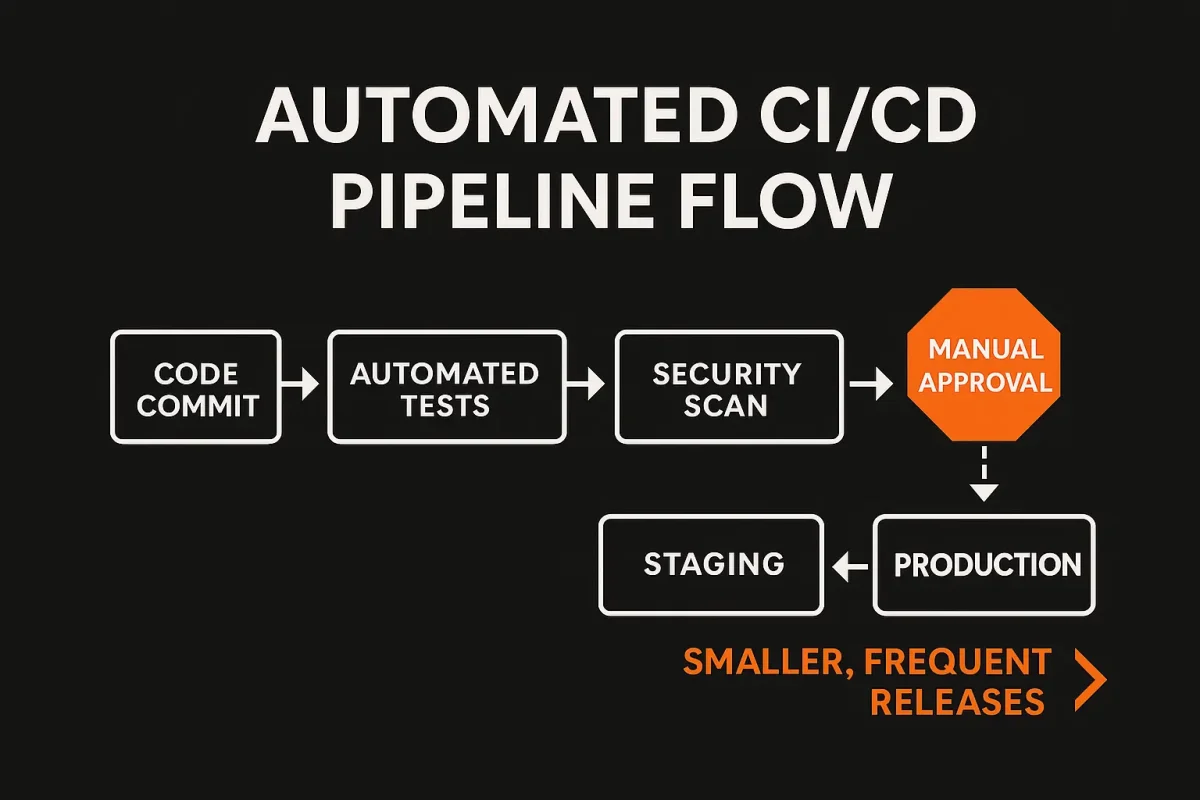
While setting up basic CI/CD has become easier with tools like GitHub Actions or Jenkins, production-ready pipelines focus on actual business value. Elite organizations can achieve thousands of deployments per day not just because they have great tools, but because they structure their pipeline to minimize risk and maximize feedback.
- Smaller, Frequent Deployments
Research indicates that smaller changes (often under 50 lines of code) typically have much lower failure rates. Frequent releases also allow teams to spot and fix issues faster, lowering overall downtime. - Balanced Automation
Over-automation can be as problematic as under-automation. In highly regulated or customer-facing updates, a human approval step may still be necessary. For most routine deployments, fully automated workflows save time and let developers focus on higher-value work.
Approval Flows and Security Checks
Modern pipelines can include automated checks for security vulnerabilities, licensing, and compliance. Rather than waiting until release day to run scans, automated checks trigger at each commit. This ongoing approach shrinks the window where security flaws can sneak into production.
Case Insight: Netflix is well-known for performing thousands of daily deployments. They didn’t achieve this scale purely by picking a popular CI tool; they invested in resilient automation processes and a culture that values experimentation. Netflix’s approach is also closely tied to advanced observability and fallback strategies.
If you’re looking to modernize existing pipelines in a practical, incremental way, consider exploring our product enhancement services for a tailored roadmap.
2. Observable Systems That Provide Actionable Insights
Many DevOps failures stem from blind spots in production. Observability goes beyond basic uptime monitoring, giving teams deep insight into why something broke, where the issue originated, and how it impacts users.
- Metrics and Business Context
Leading teams monitor both technical and business metrics in real time-tracking error rates and latency alongside user transactions, feature adoption, or revenue events. By aligning system health with user or customer impact, teams can rapidly prioritize fixes that matter most to the business. - Structured Logging
Logs are more valuable when they are structured. For instance, a JSON-based format that includes fields like service name, request ID, and error code allows teams (and automated tools) to quickly filter, correlate, and analyze logs across environments. - Distributed Tracing
In microservices or multi-tier applications, tracing each request across multiple services is critical. Identifying bottlenecks or failures in a distributed environment requires unique IDs that follow a request through every step. This approach is central to Google’s site reliability engineering (SRE) practices, which emphasize robust telemetry for proactive incident management.
Practical Tip: Start small by instrumenting a single critical path or high-traffic service. Add structured logs and a tracing solution like OpenTelemetry. Observe how often issues arise, how they propagate, and what the real-time user impact looks like. Scale your observability setup gradually as you see positive returns in meantime-to-resolution.
For guidance on tying observability to broader digital initiatives, see our digital process automation piece, which connects operational metrics to actionable business outcomes.
3. Security as an Ongoing Practice (DevSecOps)
Security cannot be an afterthought in modern software delivery. A recent report from IBM Security indicates that issues caught in production can cost up to six times more to remediate than those found in development. Meanwhile, the Sonatype State of the Software Supply Chain cites a 742% rise in supply chain attacks, underscoring the need for proactive measures.
- Shift Security Left
In a DevSecOps approach, scanning for vulnerabilities happens at every step-from local development to production monitoring. Automated checks for known CVEs (Common Vulnerabilities and Exposures) or malicious dependencies run each time code is committed, ensuring that security concerns are identified and addressed early. - Continuous Infrastructure Checks
Using Infrastructure as Code (IaC) solutions, teams encode their cloud and server configurations in version control. Every change to infrastructure is then tested, scanned, and validated-just like application code. This routine helps detect misconfigurations that might leave critical ports open or data unencrypted. - Supply Chain Management
From open-source libraries to container images, each external component poses a potential entry point for attackers. A robust DevOps workflow includes policies that verify package authenticity and automatically pull security patches when known vulnerabilities are disclosed.
Real-World Perspective: Capital One famously leveraged AWS and DevOps principles to speed up secure deployments. They established policies and continuous checks that drastically reduced provisioning times. According to public case studies, their infrastructure provisioning time dropped by more than 99%, all while meeting strict compliance requirements.
If you’re modernizing a legacy environment and want to embed security early, our legacy system modernization guide outlines how DevOps and secure-by-design principles can coexist, even in older tech stacks.
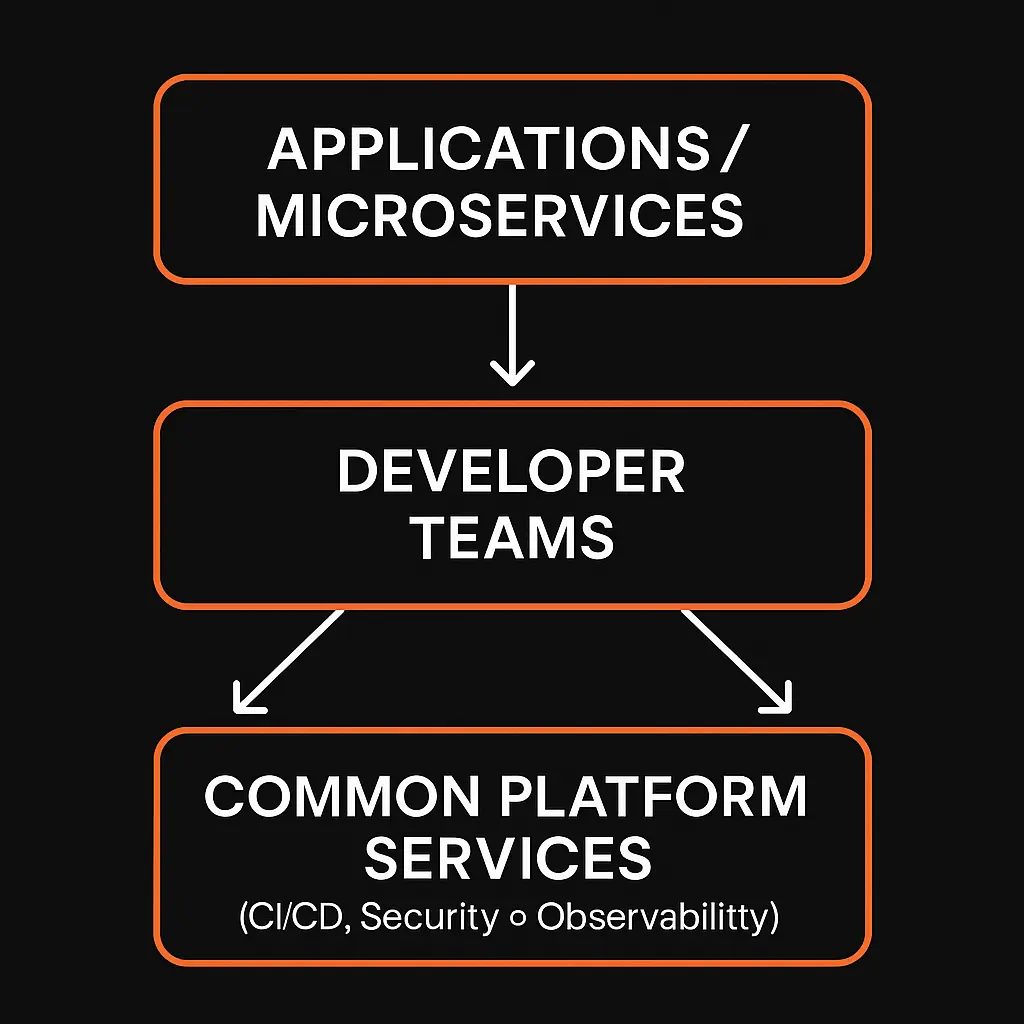
4. Platform Engineering to Scale DevOps
DevOps practices that work for a small startup can stall in a larger enterprise. As the number of teams, microservices, and deployments expands, each group faces repetitive tasks-from provisioning environments to applying security rules. Platform engineering is the answer to this complexity: it centralizes common needs so developers can focus on building features, not reinventing the wheel.
- Why Platform Engineering Matters
Gartner predicts that by 2026, 80% of large software engineering organizations will have dedicated platform teams. A well-designed internal platform offers developers self-service capabilities: spinning up test environments, hooking into CI/CD, or adding observability with minimal manual steps. - Standardization with Flexibility
An effective platform offers consistent workflows, ensuring security and governance across all teams. At the same time, it remains flexible enough for each product squad to tailor components as needed. This approach dramatically reduces onboarding time and config drift. - Measuring Platform Success
Key metrics include developer productivity (time to first deploy), incident resolution speed, and platform adoption. If developers regularly bypass your platform, it suggests the platform either lacks critical features or doesn’t solve their daily pain points. True success is when teams voluntarily leverage platform services because they see real value.
For enterprise-scale consulting on platform strategy, explore our tech consulting services to discover how standardized workflows can expedite delivery while reducing costs.
Putting It All Together: A Pragmatic DevOps Roadmap
A practical DevOps implementation doesn’t rely on a sweeping, top-down transformation. Instead, it iterates step by step, guided by data:
- Identify Bottlenecks and Goals
Examine your current development and release process. Are long test cycles slowing you down? Are you incurring high costs from late security checks? Clarify the specific business outcomes-such as reducing lead time by 30% or cutting security patching costs by half. - Start Small With a Single Team
Pilot your initial DevOps approach on one product team or service. Begin by automating core tests, introducing structured logs, and embedding lightweight security checks. Measure metrics like deployment frequency, lead time, and mean time to recovery. - Strengthen Observability and Security
As deployments accelerate, a robust monitoring and alerting system will provide confidence. Add traceability and verify you can quickly identify and fix production issues. Expand your security scans to catch vulnerabilities in code, dependencies, and infrastructure configurations. - Scale Through Platform Engineering
Once you prove success in a smaller setting, standardize best practices in a shared platform. Offer developer-friendly onboarding, environment creation, and consistent security controls. Support teams that want to adopt these shared services. Track adoption rates and productivity gains. - Refine Based on Insights
Continuously review failure patterns, user feedback, and system metrics. If certain tests create bottlenecks or if approval gates are too rigid, adjust them. DevOps is never “done”; it’s a culture of ongoing improvement, guided by tangible results.
For a deeper look at how iterative rollouts can transform the enterprise, see our Agile Transformation Roadmap, which offers step-by-step guidance for adopting Agile and DevOps practices at scale. You can also explore our digital transformation guide to understand how a modern DevOps approach integrates with broader organizational change.
Conclusion and Next Steps
Rather than chasing buzzwords or relying on a single tool, align each decision-from build scripts to security checks-with a measurable business need. Invest in observability, embed security from day one, and standardize through platform engineering as you grow.
This iterative approach reduces the risk of overhauls and keeps the focus on real-world impact-such as faster releases, fewer outages, and happier development teams. Start small, learn continuously, and expand successful patterns across the organization. By weaving DevOps practices into the broader tapestry of agile and digital transformation, you’ll be set to innovate faster and stay competitive well beyond 2025.
If you’d like personalized guidance on applying these DevOps principles in your organization, contact us to learn how we can help. Let’s work together to build a resilient, secure, and truly production-ready delivery pipeline.
Not necessarily. While certain CI/CD or container orchestration tools can streamline workflows, success hinges more on process alignment than any single product. Many companies refine their existing toolchains by adding automation scripts, stronger governance, and integrated security scans.
DevOps is a set of practices and cultural principles emphasizing collaboration, continuous delivery, and rapid feedback. Platform engineering, in turn, provides the standardized services and tooling that enable DevOps to scale across multiple teams. DevOps is the “why”; platform engineering is a key part of the “how.”
A best practice is to automate checks at every step. As soon as a developer adds a library or container image, scanning tools verify authenticity, look for known vulnerabilities, and meet compliance rules. This approach helps teams detect malicious or outdated dependencies before they ever reach production, minimizing breach risk.
Absolutely. Many organizations start with their monolith and begin introducing automation (tests, builds, deployments). Over time, as you adopt microservices or smaller modules, the same DevOps principles continue to apply. The key is incremental improvement—automate what you can, measure your outcomes, and iterate.

