
We’ve all been there. You’re making great progress on a new project, and your team is feeling confident and happy about the direction you’re heading in.
But then, seemingly out of nowhere, regression issues start popping up in the most unexpected places. It’s frustrating, time-consuming, and can seriously dampen any progress.
It has plagued many developers since, well, since coding has been a thing, I suppose. I would argue that just because it’s a common problem doesn’t mean it should be a norm.
In fact, I will argue that there are plenty of ways to prevent, diagnose, and tackle regression issues effectively.
And that’s what today’s showing will be all about.
In today’s article, we’ll explore proven strategies and techniques to minimize the impact of regression.
We’ll also cover:
- Proactive measures
- Diagnostic approaches
- Actionable steps and advice
All to keep your development boat sailing smoothly 🚢
Let’s dig in.
Prevent: Proactive Strategies to Minimize Regression
Being proactive is always better than reactive. Simply put, it saves you time and money as after reacting to an issue, you still have to enact proactive measures to avoid the problems in the future unless you fancy doing that over and over.
So, how do we go about preventing, then?
Build a Robust Architecture
A well-designed architecture is the backbone of any successful software project, web, desktop, or otherwise.
It provides a clear structure and organization for your code, thus making it easy to understand, maintain, and extend over time.
One go-to method of building one is via design patterns, proven solutions to the most common problems we all encounter.
In this domain, I’d strongly encourage you (or your dev team) to get familiar with the Design Patterns: Elements of Reusable Object-Oriented Software by the Gang of Four. It describes classic design patterns that have stood the test of time.

A Few More Principles
I would also like to draw attention to a few more principles I lean on frequently in my work.
The first one is the Single Responsibility Principle (SRP) – each component should have only one reason to change, allowing you to modify code in the future without unintended consequences.
The second one is the Dependency Inversion Principle (DIP) – by depending on abstractions rather than concrete implementations, you can create a more flexible and testable architecture.
Leverage Existing Libraries and Solutions
We aren’t in coding Olympics or creativity contests, after all.
Code is a means to an end where the end is the business product. So, don’t reinvent the wheel; use existing libraries and solutions wherever possible. They can save you time and reduce the risk of introducing new bugs.
But, as always, exercise caution and a critical eye! When choosing a library for your next project, consider factors such as:
- Popularity
- Documentation
- Compatibility with your project
- Active maintenance
- Track record of reliability and performance
Besides libraries, don’t eschew pre-built solutions and frameworks for common things like authentication, API integration, and data persistence. It allows you to focus on the unique aspects of your project instead of inventing fire for nth time.
But don’t just start chasing ALL THE LIBRARIES, trying to make your project some kind of a Frankenstein monster. Don’t add unnecessary dependencies to your project; keep them all up-to-date to avoid security and compatibility issues.
Utilize Code Quality and Type Checking Tools
Code quality and type-checking tools can catch potential issues before they start doing any real damage. They act as a first line of defense against regression issues.
If we’re talking webdev, then we’re talking JavaScript, so let’s talk about practical examples here.
One popular tool is ESLint, a static code analysis tool that checks for potential errors, style issues, and best practices. You can avoid many common mistakes by continuing it with a set of customized rules and doing regular scans.
Another one that I love is JSDoc, a tiny thing that lets you add annotations to your JS code. Adding these annotations can help you catch type-related errors and make your code more self-documenting.
But, at the end of the day, you might not even need any of those as most popular, tried, and true IDEs, like Visual Studio code, have plenty of built-in code quality and type-checking features.
Diagnose: Techniques to Identify and Detect Regression
But, if perfect code is a thing…I haven’t found it yet. Shoot me a message on LinkedIn if you ever do; I would love to see it.
What this means, in practice, is that some regression is inevitable simply because we are humans.
It’s no excuse to give up, no. Instead, it means that we need to have robust measures in place to diagnose and assess regression issues that our project might have.
Comprehensive Testing Strategy
Testing is fundamental to preventing and detecting regression issues, among other things. A comprehensive strategy should involve multiple testing techniques, as each one will have its benefits and use cases.
Unit Testing
These tests are the bread and butter of the testing world if you will. Unit tests are small, focused tests that verify the behavior of individual functions or classes in isolation.
Most commonly, you’d write unit tests for critical parts of your codebase, allowing you to catch regression errors early and ensure that each component works as intended.
Integration Testing
Moving up, we have integration tests. These verify that different parts of your system work together (i.e., integrate) correctly. So, for example, if you have an issue caused by the interaction between API contracts, the integration test will catch it.
End-to-end Testing
Finally, we use end-to-end testing to verify that our entire system works as it should. Think of it as a simulation of real-world scenarios that can catch regressions that might not be apparent at the lower levels of testing.
Like how I advised you to run code checkers automatically, you can (and should) do the same here by automating as much as possible.
Automated tests let you run them quickly and consistently with minimal human intervention, allowing you to catch regressions that might be missed otherwise.
Regular Code Reviews
A.k.a the bane of any junior developer, code reviews involve another developer reviewing code before it’s merged into the codebase.
Code reviews allow us to catch many issues that IDEs might have struggled with, like performance bottlenecks or security vulnerabilities.
It’s also essential for a social aspect! Through code reviews, developers exchange and share knowledge, and – most crucially – it ensures the alignment of coding philosophy and best practices.
It doesn’t mean it should be like a laid-back coffee talk, though. You still need proper guidelines and processes to get the most out of the code reviews, from a checklist of items to review to a workflow for submitting and reviewing pull requests.
Containerization, Monitoring, and Logging
Containerization technologies like Docker let you package your application and its dependencies into a single, portable unit. It makes it easier to deploy your app consistently across different environments and also makes it easier to diagnose a variety of issues.
Monitoring is the practice of collecting and analyzing data about how your app performs and behaves in real-time. I usually advise to monitor some key metrics like:
- Response time
- Error rates
- Resource utilization
By focusing on these critical metrics, you can quickly identify and fix the persistent issues.
Logging is when you pepper your code with log statements that help you capture important events and data points to understand what’s happening inside your application.
Remember what I said earlier, though? There is no need to reinvent the wheel if there is no need 😉
Tools like Elasticsearch, Logstash, and Kibana (ELK stack) provide potent capabilities for collecting, storing, and analyzing log data.
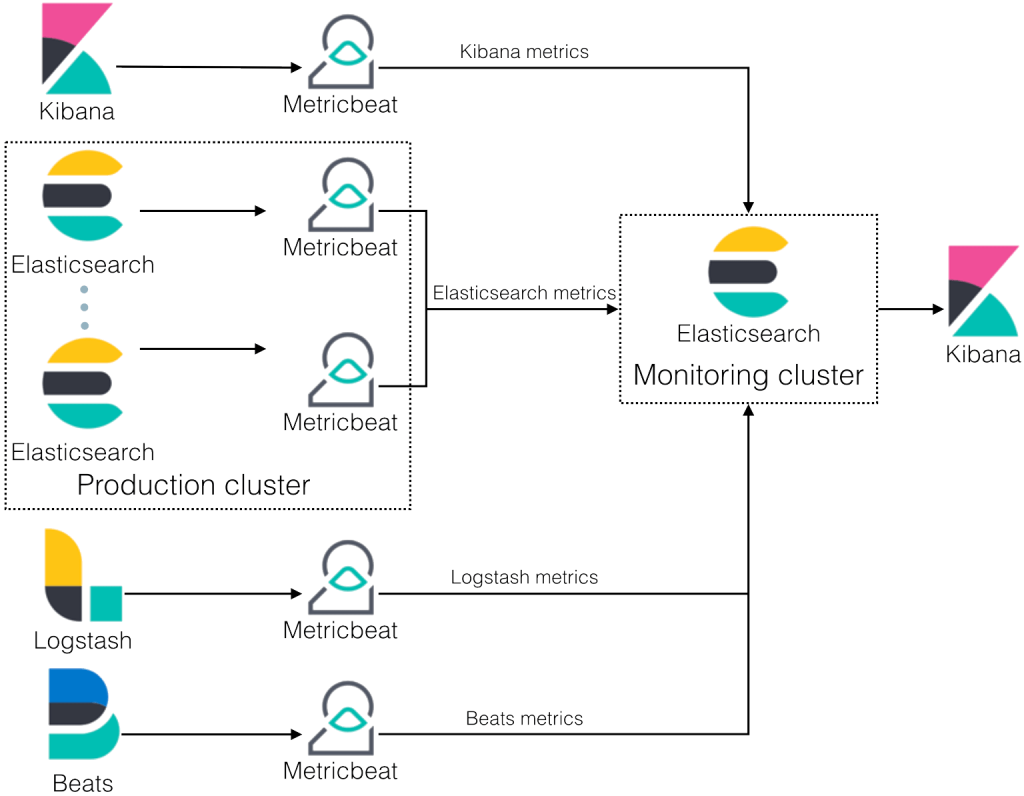
Continuous Integration and Continuous Deployment (CI/CD)
CI/CD pipelines automate the build, test, and deployment process.
Automating these processes allows us to catch regressions early and ensure that only high-quality code makes it into production.
These pipelines involve multiple stages, each with checks and validations. A typical pipeline might include stages for building the code, running unit and integration tests, and deploying it to a staging environment for manual testing.
I would focus on tools such as Jenkins, Travis CI, and GitLab CI/CD for these needs. These easily integrate with your version control system to provide you with a set of powerful features for automating builds, tests, and deployments.
Tackle: Actionable Steps to Address and Resolve Regression
And here we are. The regression has been properly diagnosed and identified. What do now?
The next step is to address and resolve the issue, but, as always, we need to be a bit clever.
Refactoring Techniques
Refactoring is the process of improving code without changing its behavior. Refactoring addresses regression issues by strengthening the codebase’s design, readability, and maintainability.
As a guideline, I would turn your attention to these refactoring techniques and procedures.
- DRY (Don’t Repeat Yourself) Principle: eliminate duplicated code by extracting common functionality into reusable functions, classes, or modules.
- Single Responsibility Principle (SRP): each class, function, or module should have a single, well-defined responsibility. It makes your code more modular, easier to understand, and less error-prone.
- Replace Conditional with Polymorphism: replace complex conditionals with objects that encapsulate the varying behavior.
- Rename Variable/Function: sounds simple, but giving variables clear, descriptive names means that it’s a lot easier to read and maintain.
- Extract Method: break up large functions into smaller, more targeted ones.
These are just a few; I’m sure there are many more. Regardless of which ones you will focus on, it’s essential to do so in a controlled, incremental way, and frequently test after each iteration. For refactoring, I would also suggest tools like ESLint and Prettier that can make identifying and fixing standard code style issues easier.
Targeted Unit Testing
We’ve talked about unit tests already, and now let’s talk about targeted ones!
These are designed to verify the behavior of a specific piece of code you identified as the source of regression. When writing these unit tests, it’s crucial to consider edge cases, boundary conditions, and other potential sources of errors or unexpected behavior.
But don’t neglect your old friends either! While you’re already at the test writing board, review and update existing tests to ensure they are still relevant and practical. After all, your codebase is constantly evolving, so older tests might become obsolete or outdated with time.
Continuous Improvement of Development Practices
Ultimately, regression is a human error. Thus, while it’s essential to have all checks and balances to ensure that regression is dealt with quickly, we must understand that it will be a repeating issue unless we learn from our mistakes and integrate these new lessons into our development baseline.
To help you on that path, conduct regular retrospectives and post-mortem analyses after each significant issue has been dealt with. Your team needs to discuss what went well and what didn’t and how they can learn and move forward.
embrace the mistakes because they will happen
Anna Tukhtarova, CTO DevPulse
But don’t neglect your staff’s training and well-being either. We are in a mercurial industry where new practices and knowledge emerge on a considerably quick timescale. So, give your team opportunities to learn new skills, stay up-to-date on the best practices, and share knowledge with other team members.
And, perhaps the most soft advice in all this tech-oriented spiel: embrace the mistakes because they will happen. Your dev team will be more confident and bold about resolving and fixing errors like regression. If they have complete confidence, they won’t be “punished” for it. Creating a punitive and hostile workplace atmosphere doesn’t mean mistakes won’t happen. It means that your devs will just get better at obfuscating them.
Conclusion
Ok, so just a quick recap on what we have learned today
- Preventing regressions:
- Build a robust architecture using design patterns and principles like SOLID
- Leverage existing libraries and solutions to avoid reinventing the wheel
- Utilize code quality and type-checking tools to catch potential issues early
- Diagnosing regressions:
- Implement a comprehensive testing strategy, including unit, integration, and end-to-end tests
- Conduct regular code reviews to identify and address potential problems
- Leverage containerization, monitoring, and logging for better visibility and reproducibility
- Utilize CI/CD pipelines to automate testing and catch regressions early
- Tackling regressions:
- Apply refactoring techniques to improve code quality and maintainability
- Write targeted unit tests to address specific regression issues
- Continuously improve development practices through retrospectives, training, and collaboration.
Sounds like a lot? Well, I’m not going to lie, cause it is. Regression is a tough nut to crack, not to mention that it kinda goes against what developers love to do: creating new things!
Implementing these strategies requires a blend of expertise, experience, and discipline. So, whether you’re only at the foothill, thinking about starting a new custom software project to help your business venture, or wrangling with an existing project, you need a team that has cracked and eaten many of these figurative nuts.
And why would you pick DevPulse over any other team out there? For today’s topic, the answer is more than trivial: before diving into web dev, we’ve had over a decade of experience creating complex desktop C++ applications.
As we’ve learned today, the more complex the project, the more complicated the regression. And after we’ve dealt with it for so many years? Writing web projects feels like finally taking our training weights off.
So, if you really want to see what we are all about, let’s talk and make your next project a reality.
FAQ
What are regression issues in custom software development?
Regression issues occur when new changes or updates to a software application cause previously functioning features to break or degrade. These issues can arise due to various factors, such as code changes, dependencies, or environment variations, and can negatively impact the user experience and overall software quality.
What are some key strategies for preventing regression issues in custom software development?
Some key strategies for preventing regression issues include:
- Building a robust and modular software architecture that adheres to design principles like SOLID
- Implementing a comprehensive testing strategy that includes unit, integration, and end-to-end tests
- Leveraging automation tools for continuous integration and continuous deployment (CI/CD)
- Conducting regular code reviews to identify and address potential issues early
- Fostering a culture of code quality, collaboration, and continuous improvement within the development team
Why is it important to prevent and tackle regression issues?
Preventing and tackling regression issues is crucial in custom software development because they can lead to
- Delayed project timelines and increased development costs
- Diminished user satisfaction and trust in the software
- Increased support and maintenance burden for the development team
- Potential loss of business opportunities and revenue
By proactively addressing regression issues, development teams can ensure a smoother, more efficient development process and deliver high-quality, reliable software to their users.
